Пособие по основам работы с LangGraph
📚 Часть 1: Теория графов — Фундамент для понимания
Граф — это математическая структура, которая моделирует отношения между объектами. В компьютерных науках это нелинейная структура данных, где связи могут быть сложнее, чем просто "соседство".
Граф состоит из двух ключевых элементов:
- Вершины (Nodes): Основные объекты или точки данных. В LangGraph это функции или компоненты вашего агента.
- Рёбра (Edges): Связи между вершинами, определяющие, как состояние или данные перемещаются по системе. В LangGraph это переходы между узлами.
Для работы с LangGraph полезно понимать несколько базовых концепций:
| Концепция | Определение | Аналог в LangGraph |
|---|---|---|
| Путь / Цепь | Последовательность смежных вершин и рёбер. | Маршрут выполнения агента от старта до финиша. |
| Цикл | Путь, в котором начальная и конечная вершины совпадают. | Механизм, позволяющий агенту повторять действия (например, задавать уточняющие вопросы). |
| Связный граф | Граф, где между любыми двумя вершинами существует путь. | Корректно построенный workflow, где у каждого узла есть вход и выход. |
| Ориентированный граф | Граф, рёбра которого имеют направление. | Все графы в LangGraph ориентированы — состояние течёт по заданному направлению рёбер. |
| Взвешенный граф | Граф, где рёбрам или вершинам присвоены числовые значения ("веса"). | Решение о переходе по тому или иному ребру может зависеть от "веса" — результата условной проверки. |
⚙️ Часть 2: LangGraph в деталях
LangGraph — это низкоуровневый фреймворк для оркестрации агентов: долгоживущих, сохраняющих состояние и способных выполнять сложные задачи. В отличие от линейных цепочек LangChain, LangGraph позволяет создавать графы любой сложности с ветвлениями, циклами и параллельным выполнением.
Ключевые архитектурные компоненты LangGraph показаны на схеме ниже. Это основа, на которой строятся все агенты:
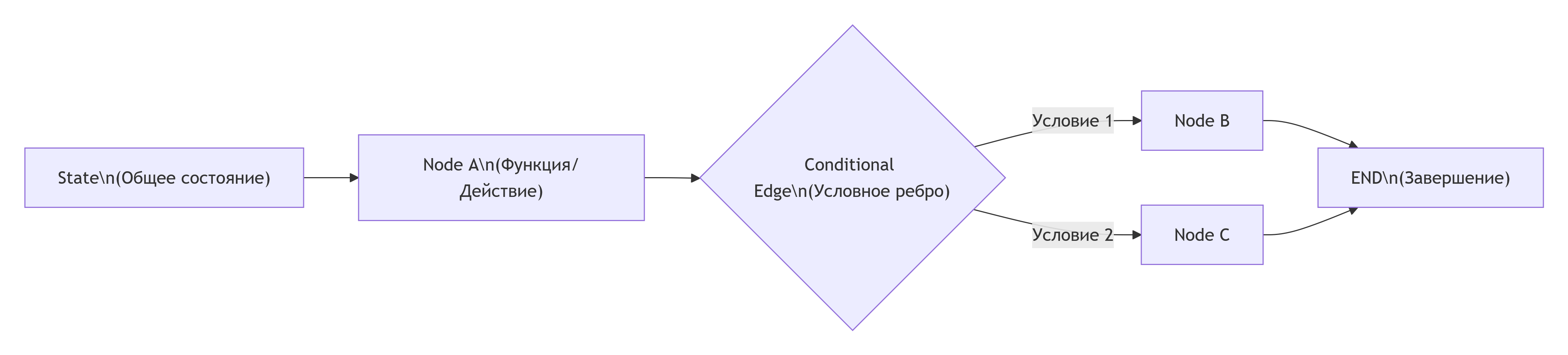
Давайте подробно разберем, как работает каждый компонент.
1. Состояние (State)
Это центральный объект, который хранит все данные, передаваемые между узлами графа. Обычно это словарь (например, TypedDict в Python). Состояние должно быть изменяемым (mutable), так как каждый узел может его обновлять.
Пример определения состояния для процесса написания шутки:
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
class State(TypedDict):
topic: str
joke: str
improved_joke: str
final_joke: str
2. Узлы (Nodes)
Это основные вычислительные единицы. Каждый узел — это функция, которая принимает текущее состояние, выполняет логику и возвращает обновление для состояния. Функция может вызывать LLM, работать с инструментами или выполнять любую другую логику.
Пример узла, который генерирует шутку:
def generate_joke(state: State):
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
3. Рёбра (Edges)
Они определяют поток выполнения. В LangGraph есть три основных типа:
- Обычные рёбра: Линейный переход от одного узла к другому.
- Условные рёбра: Решение о следующем узле принимается на основе результата функции-маршрутизатора.
- Рёбра начала и конца: Специальные константы START и END.
Пример добавления рёбер при построении графа:
workflow = StateGraph(State)
workflow.add_node("generate_joke", generate_joke)
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke",
check_punchline, # Функция, возвращающая "Pass" или "Fail"
{"Pass": END, "Fail": "improve_joke"}
)
🛠️ Часть 3: Практические шаблоны в LangGraph
Теперь рассмотрим, как компоненты складываются в полезные архитектуры.
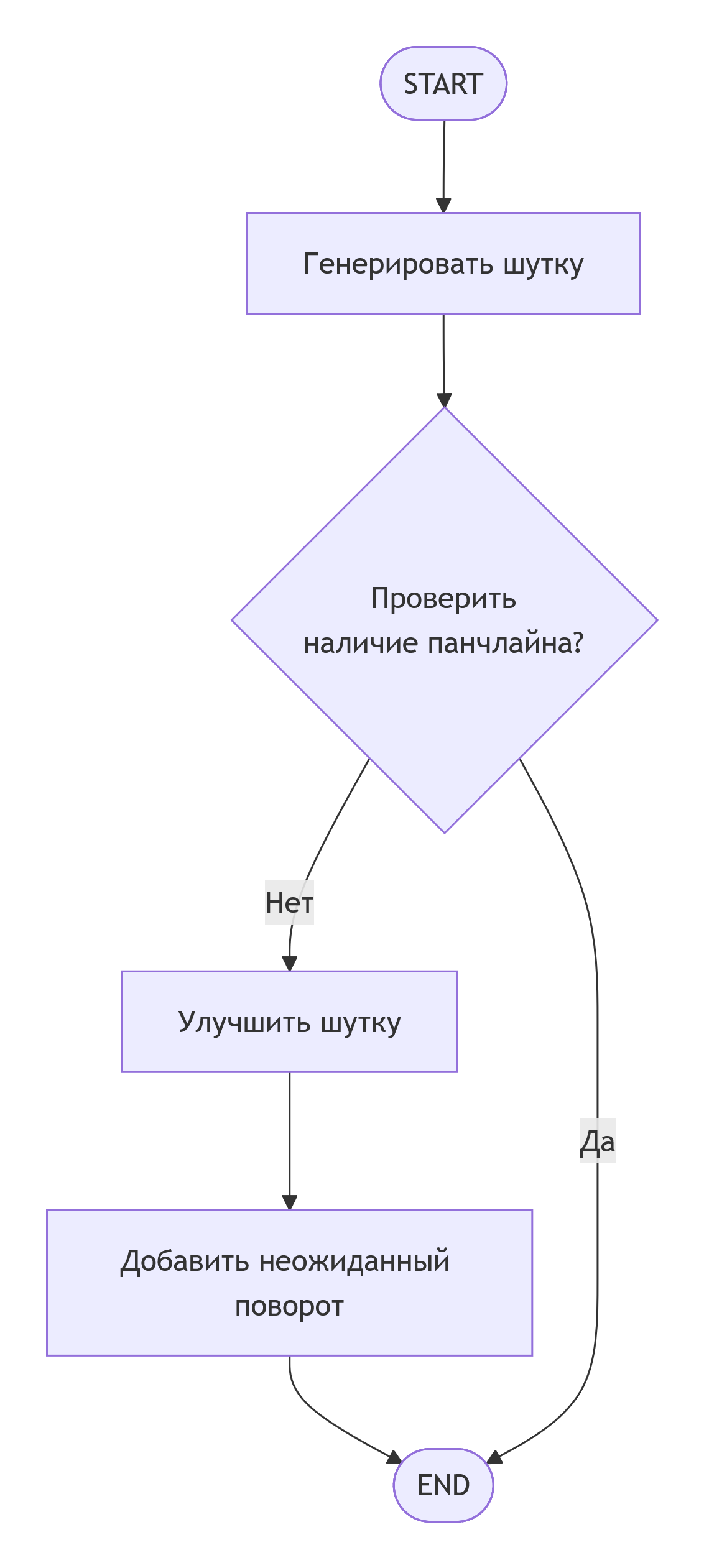
Шаблон 1: Последовательная цепочка с условием
Этот шаблон имитирует человеческое мышление: выполнить действие, проверить результат и в зависимости от него выбрать следующий шаг.
Процесс выглядит следующим образом:
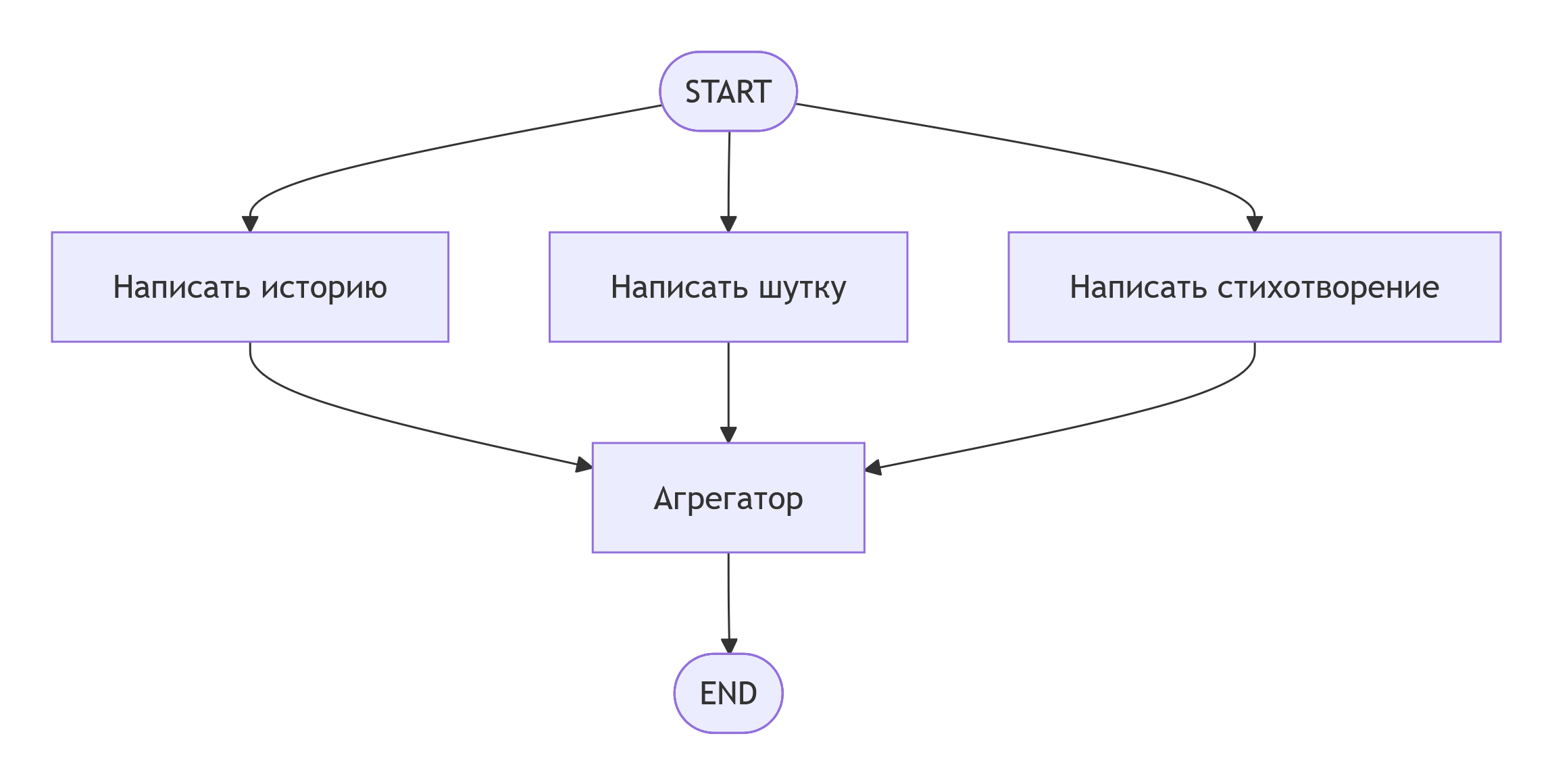
Шаблон 2: Параллельное выполнение
Используется для ускорения работы или повышения надёжности за счёт одновременного запуска нескольких независимых задач.
Схема параллельного выполнения трех задач с последующей агрегацией результатов:
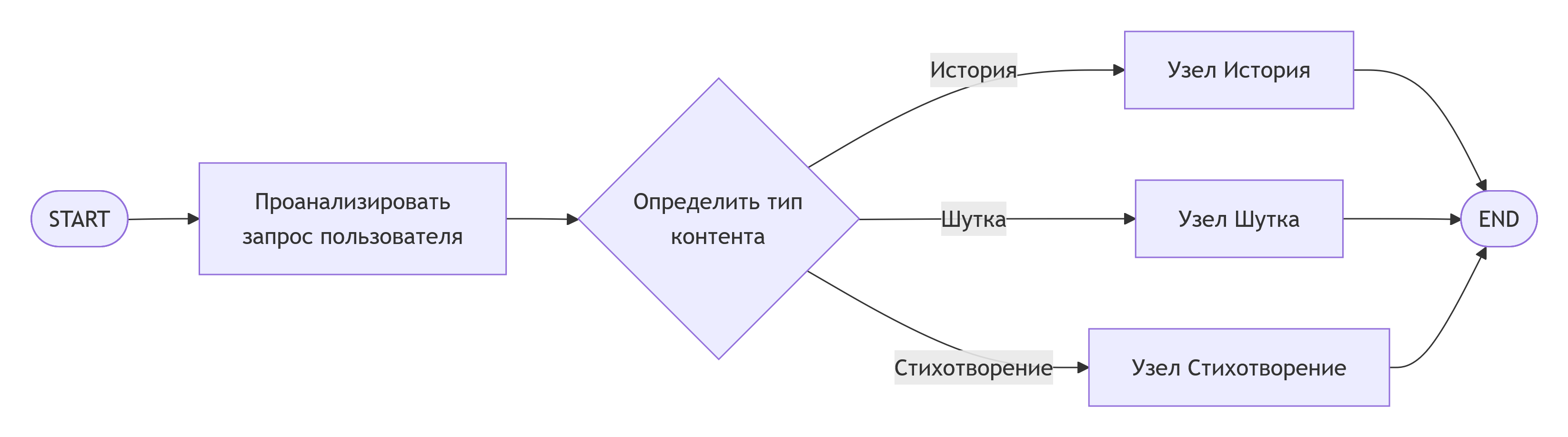
Шаблон 3: Ветвление (Routing)
Позволяет создавать "интеллектуальных" агентов, которые анализируют входные данные (например, с помощью LLM) и направляют запрос по нужному пути.
Процесс принятия решения о типе запроса и его маршрутизации:
Шаблон 4: Агент с инструментами (Tools) и циклом
Это основа для создания по-настоящему мощных агентов, которые могут взаимодействовать с внешним миром. Ключевое отличие агента от простого чат-бота — способность планировать, использовать инструменты и адаптироваться на основе результатов.
Схема работы агента с инструментами в цикле:
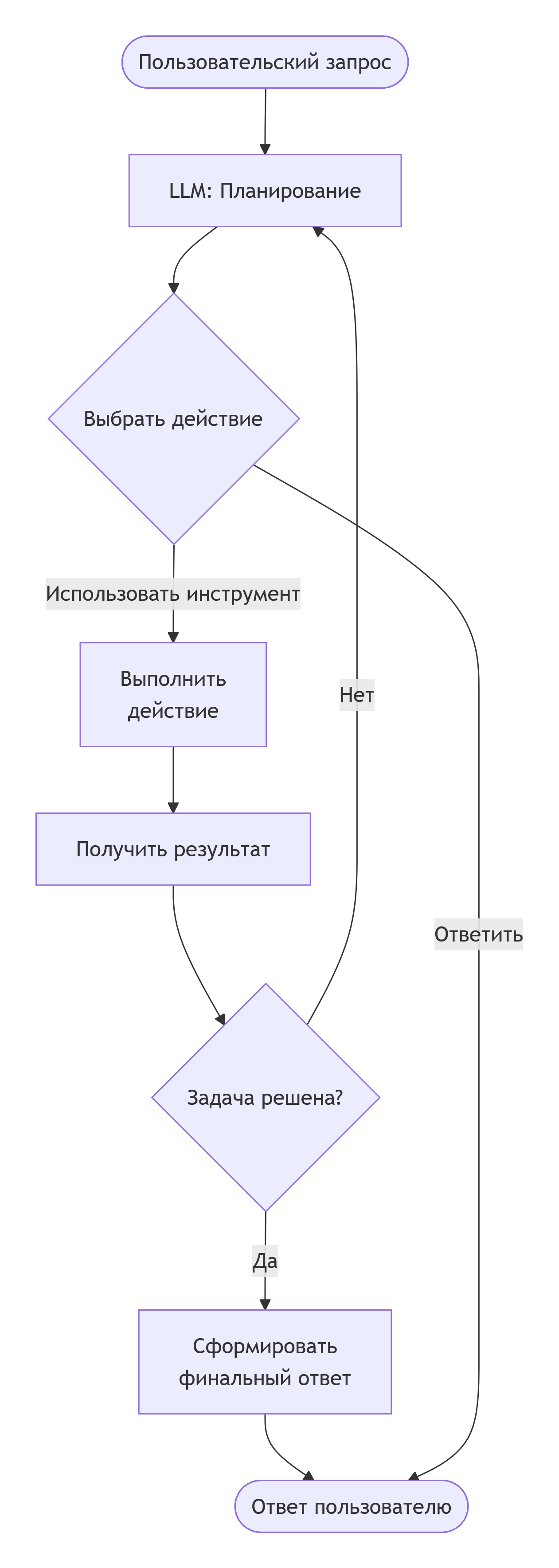
В этом цикле LLM выступает в роли "мозга", который на каждом шаге решает, какой инструмент применить или дать финальный ответ. Инструменты — это функции, дающие агенту "руки" для работы с внешними системами: выполнения запросов к БД, вызова API, работы с файлами.
🚀 Часть 4: Следующие шаги и рекомендации
- Начните с простого. Реализуйте базовый линейный граф, чтобы понять работу со State и узлами.
- Добавьте условие. Усложните граф, добавив условное ребро и функцию-маршрутизатор.
- Дайте агенту "руки". Создайте простой инструмент (например, калькулятор или поиск в Wikipedia) и интегрируйте его в граф с циклом, как в Шаблоне 4.
- Используйте LangSmith для отладки. Этот инструмент предоставляет глубокую визуализацию выполнения графа, что незаменимо для сложных агентов.
- Помните о безопасности. Когда агент получает доступ к инструментам, важно продумать систему контроля и проверок (human-in-the-loop), особенно для операций записи или критических действий.
Главное преимущество LangGraph — в контроле и гибкости. Вы проектируете не "чёрный ящик", а детализированную когнитивную архитектуру, которую можно точно настроить под свою задачу.
Вот полный рабочий пример агента для генерации и оценки шуток с использованием LangGraph. Этот код демонстрирует все ключевые концепции из пособия.
📁 Структура проекта
joke_agent/ ├── main.py # Основной файл с графом ├── requirements.txt # Зависимости └── .env # Переменные окружения (API-ключи)
1. requirements.txt
langgraph langchain-openai python-dotenv
2. .env (создайте этот файл)
OPENAI_API_KEY=ваш_ключ_здесь
3. main.py — полный код примера
import os
from typing import Literal, TypedDict
from dotenv import load_dotenv
from langgraph.graph import StateGraph, END, START
from langchain_openai import ChatOpenAI
# Загружаем переменные окружения
load_dotenv()
# ==================== 1. ОПРЕДЕЛЕНИЕ СОСТОЯНИЯ ====================
class AgentState(TypedDict):
"""Состояние нашего агента. Все узлы могут читать и записывать эти поля."""
user_request: str # Что хочет пользователь
initial_joke: str # Первоначальная шутка
joke_rating: int # Оценка шутки (1-10)
analysis: str # Анализ качества шутки
improved_joke: str # Улучшенная версия
final_output: str # Финальный результат для пользователя
# ==================== 2. ИНИЦИАЛИЗАЦИЯ LLM ====================
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.7,
api_key=os.getenv("OPENAI_API_KEY")
)
# ==================== 3. ОПРЕДЕЛЕНИЕ УЗЛОВ (NODES) ====================
def generate_joke(state: AgentState):
"""Узел 1: Генерация первоначальной шутки"""
print("🔹 Узел 'generate_joke': Генерирую шутку...")
prompt = f"Придумай короткую смешную шутку на тему: {state['user_request']}. Шутка должна быть на русском языке."
response = llm.invoke(prompt)
return {"initial_joke": response.content}
def analyze_joke(state: AgentState):
"""Узел 2: Анализ и оценка шутки"""
print(f"🔹 Узел 'analyze_joke': Анализирую шутку...")
print(f" Текст шутки: {state['initial_joke']}")
prompt = f"""Проанализируй эту шутку и дай оценку от 1 до 10:
Шутка: "{state['initial_joke']}"
Верни ответ строго в формате JSON:
{{
"rating": число от 1 до 10,
"analysis": "короткий анализ на русском, почему такая оценка"
}}
"""
response = llm.invoke(prompt)
# Парсим ответ (упрощённо)
content = response.content
rating = 5 # значение по умолчанию
# Простой парсинг
if '"rating":' in content:
try:
# Ищем число после "rating":
start = content.find('"rating":') + 9
end = content.find(',', start)
if end == -1:
end = content.find('}', start)
rating_str = content[start:end].strip()
rating = int(rating_str)
except:
pass
analysis = f"Оценка: {rating}/10. " + content[:100] + "..."
return {
"joke_rating": rating,
"analysis": analysis
}
def improve_joke(state: AgentState):
"""Узел 3: Улучшение шутки, если она плохая"""
print(f"🔹 Узел 'improve_joke': Улучшаю шутку (текущая оценка: {state['joke_rating']}/10)...")
prompt = f"""Улучши эту шутку. Сделай её смешнее и остроумнее.
Исходная шутка: "{state['initial_joke']}"
Анализ проблемы: {state['analysis']}
Верни ТОЛЬКО улучшенную версию шутки, без пояснений."""
response = llm.invoke(prompt)
return {"improved_joke": response.content}
def finalize_output(state: AgentState):
"""Узел 4: Подготовка финального ответа для пользователя"""
print("🔹 Узел 'finalize_output': Формирую финальный ответ...")
if state.get('improved_joke'):
# Если шутку улучшали
output = f"""🎭 **Ваша шутка на тему "{state['user_request']}":**
**Первоначальный вариант:**
{state['initial_joke']}
⚠️ *Наш анализ:* {state['analysis']}
**Улучшенный вариант:**
{state['improved_joke']}
Надеемся, стало смешнее! 😄"""
else:
# Если шутка и так хорошая
output = f"""🎭 **Ваша шутка на тему "{state['user_request']}":**
{state['initial_joke']}
✅ *Наш анализ:* {state['analysis']}
Отличная шутка! Оценка: {state['joke_rating']}/10 🏆"""
return {"final_output": output}
# ==================== 4. ФУНКЦИЯ МАРШРУТИЗАЦИИ ====================
def should_improve_joke(state: AgentState) -> Literal["good_enough", "needs_improvement"]:
"""
Условное ребро: решает, нужно ли улучшать шутку.
Возвращает название следующего узла.
"""
rating = state.get('joke_rating', 0)
if rating >= 7:
print(f" Маршрутизатор: шутка хорошая ({rating}/10), идём к финалу")
return "good_enough"
else:
print(f" Маршрутизатор: шутка слабая ({rating}/10), нужно улучшить")
return "needs_improvement"
# ==================== 5. ПОСТРОЕНИЕ ГРАФА ====================
def create_joke_agent():
"""Создаём и конфигурируем граф агента"""
print("🛠️ Создаю граф агента...")
# 1. Создаём граф с нашим состоянием
workflow = StateGraph(AgentState)
# 2. Добавляем узлы
workflow.add_node("generate", generate_joke)
workflow.add_node("analyze", analyze_joke)
workflow.add_node("improve", improve_joke)
workflow.add_node("finalize", finalize_output)
# 3. Добавляем рёбра
workflow.add_edge(START, "generate") # Старт -> Генерация
workflow.add_edge("generate", "analyze") # Генерация -> Анализ
# 4. УСЛОВНОЕ РЕБРО: после анализа решаем, что делать дальше
workflow.add_conditional_edges(
"analyze",
should_improve_joke, # Функция-маршрутизатор
{
"good_enough": "finalize", # Если хорошо -> финализируем
"needs_improvement": "improve" # Если плохо -> улучшаем
}
)
# 5. Линейные рёбра от улучшения к финалу
workflow.add_edge("improve", "finalize")
workflow.add_edge("finalize", END)
# 6. Компилируем граф
print("✅ Граф создан и скомпилирован!")
return workflow.compile()
# ==================== 6. ЗАПУСК АГЕНТА ====================
def run_agent():
"""Функция запуска агента с примером запроса"""
# Создаём агента
agent = create_joke_agent()
# Начальное состояние
initial_state = AgentState(
user_request="программисты и кофе",
initial_joke="",
joke_rating=0,
analysis="",
improved_joke="",
final_output=""
)
print("\n" + "="*50)
print("🚀 ЗАПУСК АГЕНТА")
print("="*50)
print(f"Запрос: {initial_state['user_request']}")
print("="*50 + "\n")
# Запускаем граф
try:
result = agent.invoke(initial_state)
print("\n" + "="*50)
print("📊 РЕЗУЛЬТАТ РАБОТЫ АГЕНТА")
print("="*50)
print(result['final_output'])
print("="*50)
# Дополнительная информация
print("\n📈 ПРОМЕЖУТОЧНЫЕ РЕЗУЛЬТАТЫ:")
print(f"• Первоначальная шутка: {result['initial_joke'][:80]}...")
print(f"• Оценка: {result['joke_rating']}/10")
if result.get('improved_joke'):
print(f"• Улучшенная шутка: {result['improved_joke'][:80]}...")
except Exception as e:
print(f"❌ Ошибка: {e}")
if "API key" in str(e):
print("Проверьте, что вы добавили OPENAI_API_KEY в файл .env")
# ==================== 7. ВИЗУАЛИЗАЦИЯ ГРАФА ====================
def visualize_graph():
"""Создаём визуализацию графа (сохраняет в файл)"""
try:
agent = create_joke_agent()
# Сохраняем граф в PNG
from IPython.display import Image, display
# Для сохранения в файл
image_data = agent.get_graph().draw_mermaid_png()
with open("joke_agent_graph.png", "wb") as f:
f.write(image_data)
print("📊 Граф сохранён в файл 'joke_agent_graph.png'")
# Если запущено в Jupyter, можно отобразить
# display(Image(image_data))
except Exception as e:
print(f"⚠️ Не удалось создать визуализацию: {e}")
print("Установите: pip install pygraphviz")
# ==================== 8. ТОЧКА ВХОДА ====================
if __name__ == "__main__":
print("🤖 Агент для генерации и оценки шуток")
print("Использует LangGraph для управления workflow\n")
# Запускаем агента
run_agent()
# Создаём визуализацию (опционально)
# visualize_graph()
🎯 Как запустить:
- Установите зависимости:
pip install -r requirements.txt
-
Получите API-ключ OpenAI и добавьте его в файл .env
-
Запустите агента:
python main.py
📊 Пример вывода:
🛠️ Создаю граф агента...
✅ Граф создан и скомпилирован!
==================================================
🚀 ЗАПУСК АГЕНТА
==================================================
Запрос: программисты и кофе
==================================================
🔹 Узел 'generate_joke': Генерирую шутку...
🔹 Узел 'analyze_joke': Анализирую шутку...
Маршрутизатор: шутка слабая (4/10), нужно улучшить
🔹 Узел 'improve_joke': Улучшаю шутку (текущая оценка: 4/10)...
🔹 Узел 'finalize_output': Формирую финальный ответ...
==================================================
📊 РЕЗУЛЬТАТ РАБОТЫ АГЕНТА
==================================================
🎭 **Ваша шутка на тему "программисты и кофе":**
**Первоначальный вариант:**
Почему программист пьёт кофе? Потому что Java!
⚠️ *Наш анализ:* Оценка: 4/10. Шутка банальная...
**Улучшенный вариант:**
Почему программист предпочитает кофе без сахара?
Потому что ему хватает sweet синтаксиса в коде!
Надеемся, стало смешнее! 😄
==================================================
🔍 Что происходит в графе:
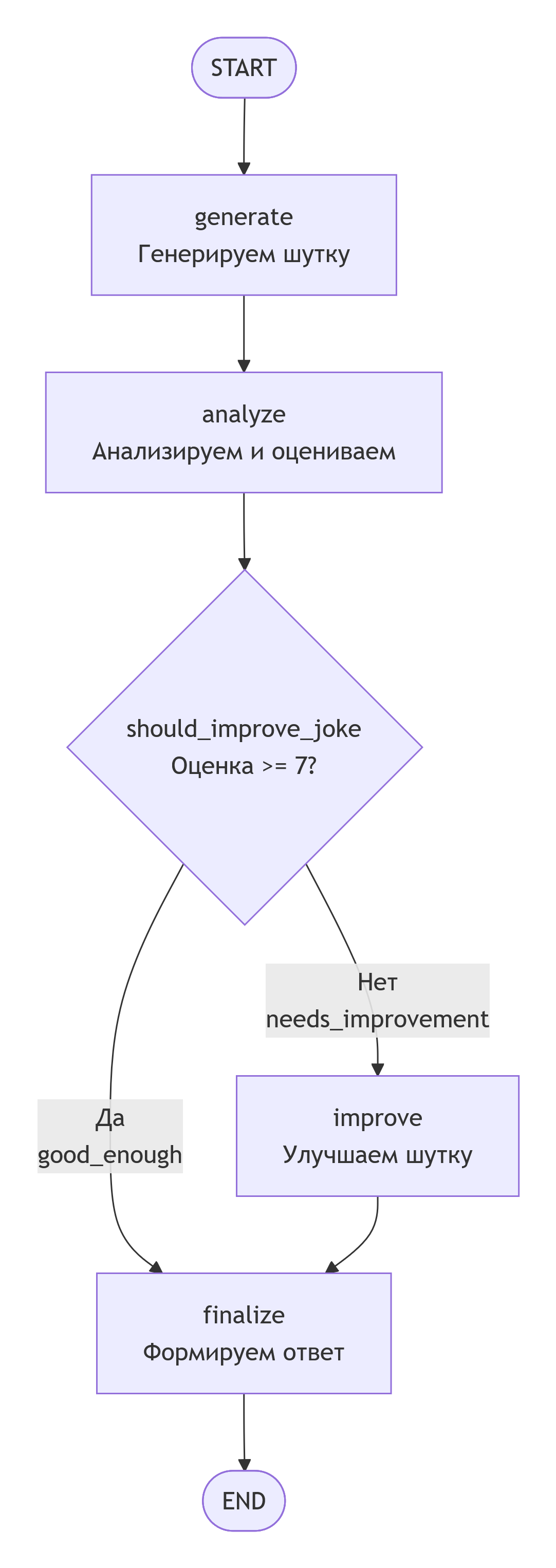
💡 Ключевые моменты примера:
- Полный цикл работы: от запроса пользователя до финального результата
- Условная логика: агент решает, нужно ли улучшать шутку
- Состояние передаётся: каждый узел видит и может изменять общее состояние
- Логирование: на каждом шаге видно, что происходит
- Готовность к расширению: можно легко добавить новые узлы или условия
Это основа, на которой можно строить более сложных агентов для любых задач!
Надеюсь, это руководство дало вам чёткое понимание как теории, так и практики. Удачи в создании интеллектуальных агентов