LM Studio: бесплатный ИИ-чат и сервер у себя на компьютере
Общие моменты работы с LM Studio
Для знакомства и работы с искусственным интеллектом очень полезно и удобно использовать LM Studio. Если кратко, то это инструмент для запуска локальных моделей ИИ (искусственного интеллекта) в формате GGUF на своем ПК (персональном компьютере) без необходимости отправки чего-либо на другие сервера в сети Интернет.

Работа строится очень просто:
1. Выбираете и загружаете одну из локальных моделей ИИ, например, Gemma 4b, Qwen 4b или другие.
2. Запускаете чат, выбираете модель и все готово.

3. Спрашиваете, получаете ответы, уточняете.

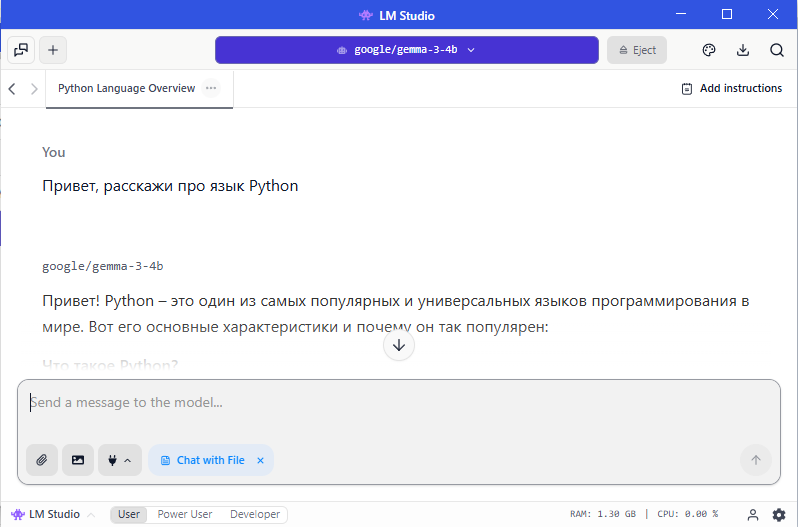
Для более качественного ответа можно при отправке запроса вложить текстовые или графические файлы. Некоторые модели работают только с текстом, другие могут проанализировать картинку/фото и сообщить, что на ней изображено.
Скорость ответов напрямую зависит от мощности ПК, на котором запущена программа LM Studio. Чем более мощный у вас ПК, тем более сложные модели можно использовать для изучения и работы.
Как развернуть на своем персональном компьютере сервер, совместимый с OpenAI API
Для продвинутых пользователей и разработчиков есть очень удобная возможность активировать LM Studio как локальный сервер с API на основе протокола OpenAI. Это дает возможность использовать его как облачные, например, ChatGPT, Grok, Deepseek, Qwen и другие. Например, я сделал себе проект для личного использования, который использует локальные модели вместо облачных API, что очень удобно и бесплатно. Использование LM Studio как сервера возможно и по локальной сети с другого компьютера, например, более мощного или с установленной игровой видеокартой RTX 3060 и выше. Более старые видеокарты тоже будут работать, но с меньшей скоростью генерации.
Включаем сервер
1. Сначала надо перевести работу с LM Studio в режим "Power User" или "Developer". Это делается через выбор вкладки в нижней части главного окна.
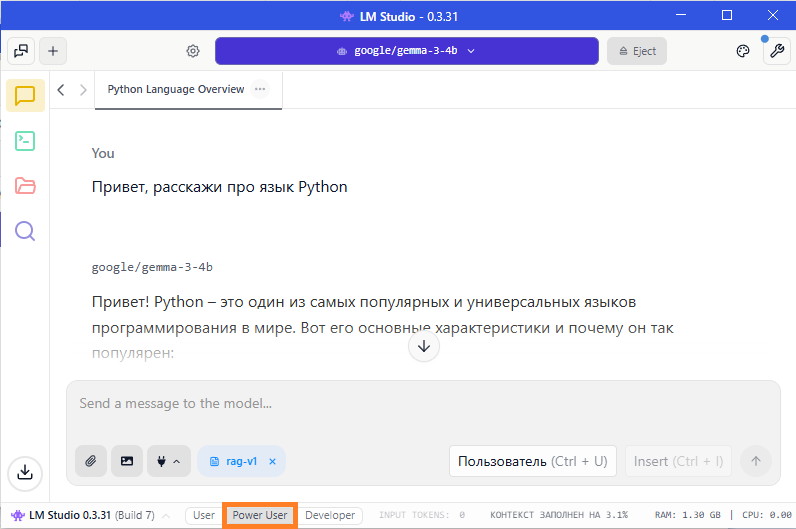
2. После этого, в левой части главного окна появляются дополнительные вкладки, нам нужно выбрать зеленую, которая предназначена для запуска и настройки работы в режиме сервера.

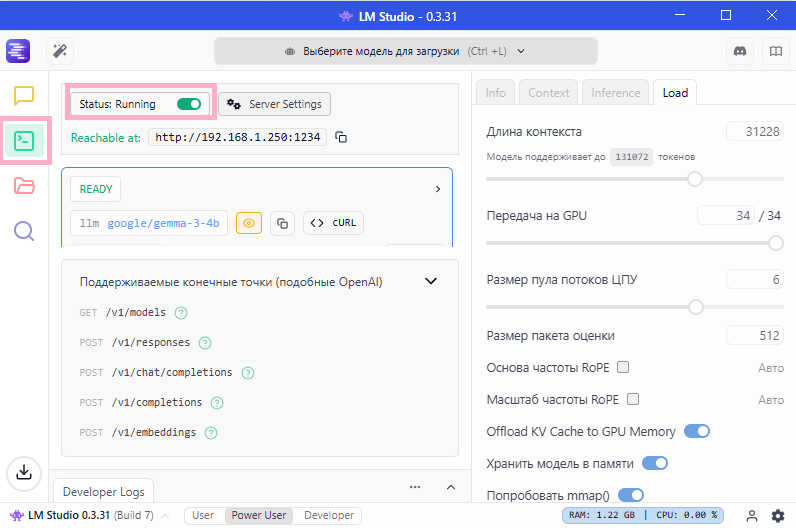
3. На этой вкладке надо активировать флажок "Status" в верхней части окна, чтобы статус сменился на "Running", а сам флажок стал включенным и зеленого цвета.
4. Далее, нам понадобится адрес сервера, например "http://192.168.1.250:1234", который мы вставим в наш код для работы.
5. Также снизу указаны доступные эндпойнты (точки входа) для работы с сервером, из них самые нужные следующие:
- GET "/v1/models" - это список доступных моделей, которые уже загружены и могут быть активированы для работы
- POST "/v1/chat/completions" - это точка обращения к LLM с запросом
Пример рабочего кода на Python
# Обязательно установите OpenAI SDK перед запуском: `pip3 install openai`
import os
from openai import OpenAI
client = OpenAI(api_key='', base_url="http://192.168.1.250:1234/v1") # путь к модели
response = client.chat.completions.create(
model="google/gemma-3-4b",
messages=[
{"role": "system", "content": "Ты опытный программист на Python"},
{"role": "user", "content": "Привет, расскажи про Python"},
],
stream=False
)
print(response.choices[0].message.content)
Пояснения к коду
Поскольку мы использовали библиотеку openai, то для нее достаточно указать путь "http://192.168.1.250:1234/" и добавить "v1", библиотека сама добавит стандартный путь "chat/completions".
Если делать обращение к серверу напрямую через запрос http, то нужно будет указать полный путь "http://192.168.1.250:1234/v1/chat/completions"
Резюме
LM Studio удобно использовать и как чат, и как сервер для тестирования при разработке своих приложений. Как показано выше, достаточно двух десятков строк кода на Python, чтобы использовать локальный сервер для работы с искусственным интеллектом.
Если у пользователя на компьютере установлена мощная видеокарта с большим объемом видеопамяти, например, RTX 4070 12GB или более мощная, то ее можно использовать и для решения некоторых практических задач. В любом случае, наличие своего сервера упрощает тестирование своих разработок, не нужно платить за использование облачных серверов.